Quantifying Generalization: CVEDIA Detection Technology vs. Seven Open Source Datasets
A research study exploring biases in open source image classification datasets and demonstrating how CVEDIA's synthetic data technology outperforms seven major real-world datasets in cross-domain generalization.
Synthetic data has developed in the academic machine learning community as an alternative to real world data collection. In this research, we explore biases found in open source image classification datasets, as well as issues present in common data annotation methods. We built a machine learning algorithm using CVEDIA’s synthetic technology to counteract biases present in seven open source datasets, and conclude that the CVEDIA algorithms generalize better than each of the real world datasets analyzed.
Background
It’s long been seen in the machine learning community that many of the barriers to robust AI models lie in the data that trains and validates them. Data collection itself is often costly and time consuming, while open datasets are often broadly defined, unspecific to individual projects, and each come with their own set of biases.
In our own research, we’ve also found that manual annotation is not without issue - the misclassification of confusing and small objects, cultural and contextual differences in definitions, and simply missing objects in a background in favour of foreground objects, all pose a problem to the generalization of a dataset.



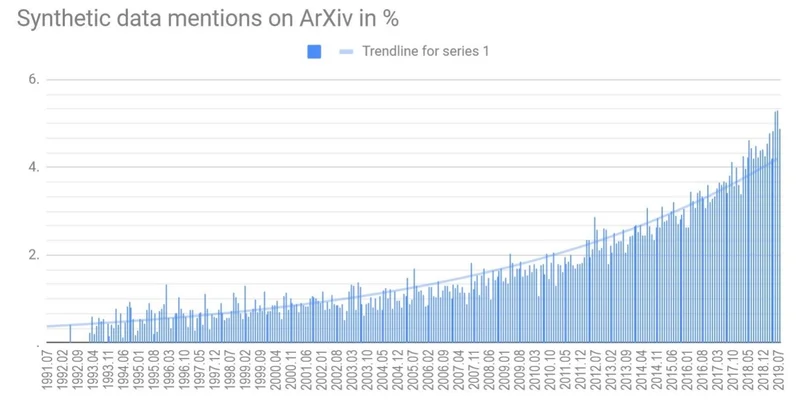
Synthetic data has been found to be a viable alternative to real world data when used correctly. However, knowledge about the use and efficacy of synthetic data has been broadly confined to academic circles. CVEDIA found that mentions of the term “synthetic data” have rapidly increased over time in academic papers on ArXiv.org, signalling a growing interest and need for the technology among data scientists.
CVEDIA speculates that due to the complex, visual nature of computer vision training sets, it’s not possible with current technology to create an unbiased dataset, as there is no effective way for its creators to fully gauge or present the biases apparent in the real world. Taking the route of synthetic data, however, allows for a model-based design, in which data can be created to effectively counteract biases.
Methodology
Our data science team selected seven popular open datasets, including both synthetic and real image datasets. We chose datasets with a variety of conditions present to compare different types of bias. Certain datasets have a fixed point of view (POV), others are mixed, some have day and night conditions, others only day, some have mixed camera quality, others a single one, etc.
Our hypothesis is that CVEDIA’s synthetic algorithms can generalize better cross-domain, therefore models trained using CVEDIA technology should perform better when presented a novel domain.
Training Conditions
- All models were trained using the same base model, RefineDet512 VGG16 COCO
- All models were trained in the full extension of their target dataset - no sampling was applied
- We fine tuned hyper parameters for each dataset to assure the highest score possible
- All models were trained using SGD
- All models were trained until they reached the highest precision (mAP) and recall (mAR) combination
- Batch size was fixed to 4 on both training and validation
- A single existing class, Car, was fine tuned
- Standard caffe augmentation stack was used
Validation Conditions
- Models were measured against each validation dataset every 100 epochs
- All dataset annotations were converted to a common format without any data loss
- Original dataset images were untouched and used as is
Cross Domain Test
Each of the datasets’ best performing models were then validated using each of the other datasets. This produced a confusion matrix that allows us to compare cross-domain performance.
CVEDIA Model
- The CVEDIA model was exclusively trained using synthetic data created by our simulation engine SynCity - which creates high-fidelity, realism-based imagery
- We applied the same base model, fine tuning, and optimization process as all other models
- Training cutoff strategy was the same as other models
Datasets Analyzed
| Name | Description | Source | Size | POV |
|---|---|---|---|---|
| Apollo | Small dataset comprised of 100 real images for validation and training | Real | 100 | Car bonnet, Cropped |
| BDD | Highly varied dataset, including day/night scenarios, different weather conditions, heavy traffic, and camera aberrations | Real | 100k | Car bonnet |
| Boxy Vehicles | Mainly composed of highway shots, with a single POV. Includes 3D annotations | Real | 137k | Car bonnet |
| Cityscape | Focused on city environments, highly diversified, daylight only | Real | 3.5k | Car bonnet |
| Kitti | Focused on European city environments, daylight only, wide camera angle | Real | 7.5k | Car bonnet, Cropped, Wide angle |
| P4B | Synthetic dataset created using GTA5. Includes city and highway environments, day/night conditions | Synthetic | 184k | Front bumper |
| Synthia SF | Extensive synthetic dataset with exclusively daylight city scenarios. Not realism-focused | Synthetic | 4.5k | Front bumper |


Dataset Bias

Before we discuss our analysis, we must address the fact that all datasets are inherently flawed. Following is a summary of annotation issues discovered during the testing process:
Apollo: Small (100 images), single POV, camera color bias
BDD: >90% of occluded objects annotated as whole yet inconsistently treated, questionable small object annotations, single POV despite large size
Boxy Vehicles: Single camera type, missing annotations especially for oncoming traffic, inconsistent bounding box sizes
Cityscapes: Single car/camera/POV, daylight only, pristine image quality, missing annotations, inconsistent bounding boxes
Kitti: Single camera/POV, missing annotations, inconsistent bounding boxes, questionable group annotations
P4B: Annotated fully occluded objects, single pixels annotated, subject car bonnet annotated, mistagged objects
Synthia SF: Single scenario/POV, mistagged objects, annotated fully occluded objects, linear camera
The Bias Problem
Every dataset and algorithm has a unique bias. Even if unnoticeable from a human perspective, biases in datasets are an inherent reality - from lighting conditions, object distribution, camera aberrations, and POV, to liberties taken by the person annotating.
The side effects of biases are many:
- Reduction of the operating envelope of a model
- Poor accuracy
- Lack of adaptability cross-domain
- Misanchored detections
Real data suffers from an additional inescapable problem - the value of a single data point, and how distributed the occurrence of feature-rich content is.
Using CVEDIA’s proprietary SynCity simulation engine, we were able to control aspects of these biases, creating linearly distributed data points specifically targeted for the model using realistic and high-fidelity imagery, and aiming for bias eradication or mitigation on a large scale.
Results
As expected, models that were trained and validated using the same dataset had the highest performance scores, due to the inability of the model to detect bias when using itself as a reference. Looking at how each dataset performed compared against other datasets, however, flaws and biases surfaced.
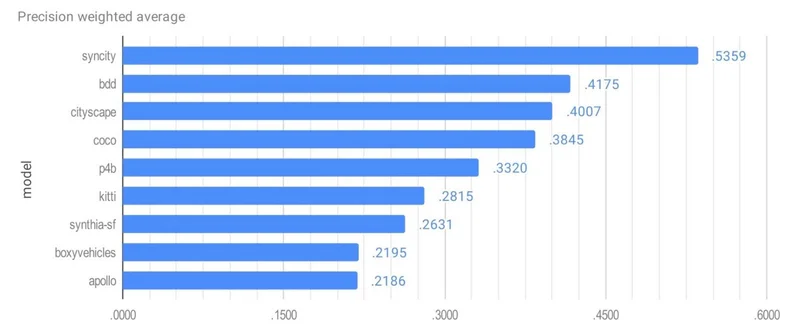
Precision Weighted Average (mAP)
| Model | Score |
|---|---|
| SynCity (CVEDIA) | 0.5359 |
| BDD | 0.4175 |
| Cityscape | 0.4007 |
| COCO | 0.3845 |
| P4B | 0.3320 |
| Kitti | 0.2815 |
| Synthia-SF | 0.2631 |
| Boxy Vehicles | 0.2195 |
| Apollo | 0.2186 |
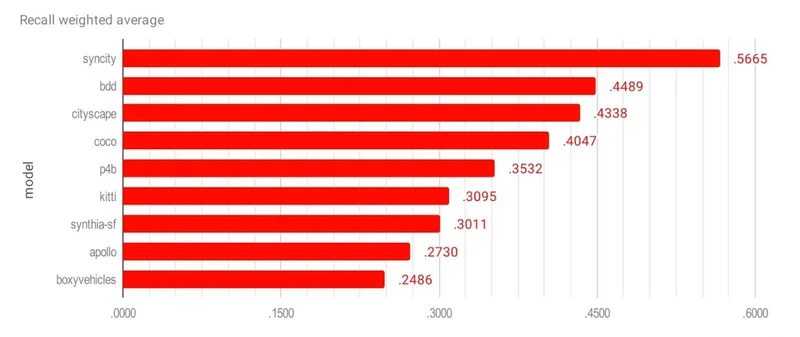
Recall Weighted Average (mAR)
| Model | Score |
|---|---|
| SynCity (CVEDIA) | 0.5665 |
| BDD | 0.4489 |
| Cityscape | 0.4338 |
| COCO | 0.4047 |
| P4B | 0.3532 |
| Kitti | 0.3095 |
| Synthia-SF | 0.3011 |
| Apollo | 0.2730 |
| Boxy Vehicles | 0.2486 |
Performance Analysis
Particular datasets performed worse than others, namely Boxy Vehicles and P4B. In our analysis this seemed to be due to mislabelled annotations - effectively damaging model convergence, making a portion of the training data unlearnable as it gives the model mixed signals. Models trained on these datasets performed worse than the baseline metric cross-domain and with significantly reduced precision.
Size Breakdown Results
We defined object size based on bounding box area:
- Large: more than 9216 pixels
- Medium: between 1024 and 9216 pixels
- Small: less than 1024 pixels
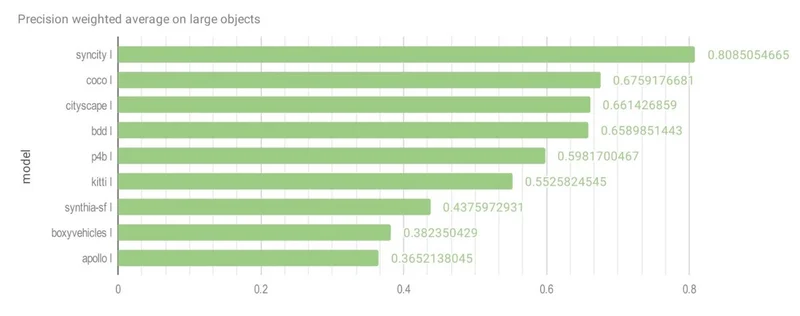
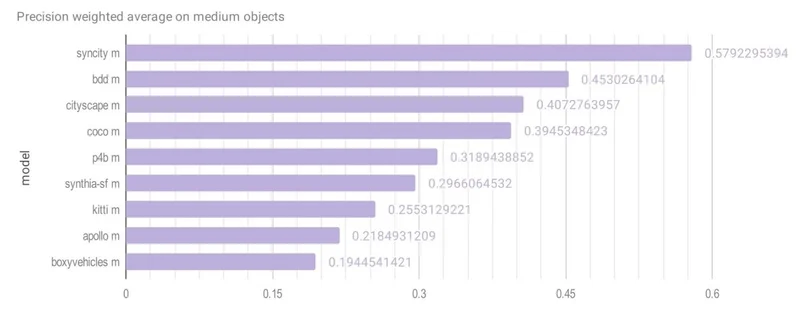
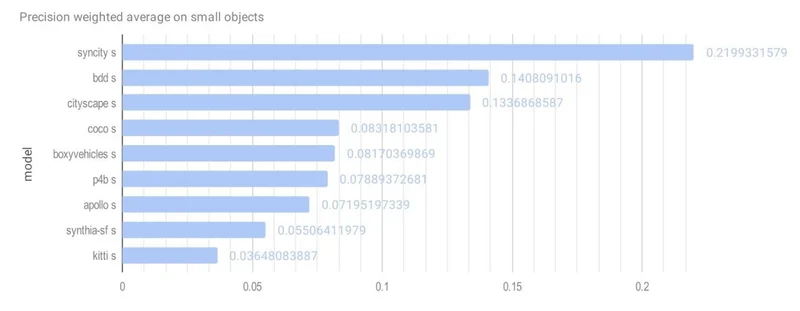
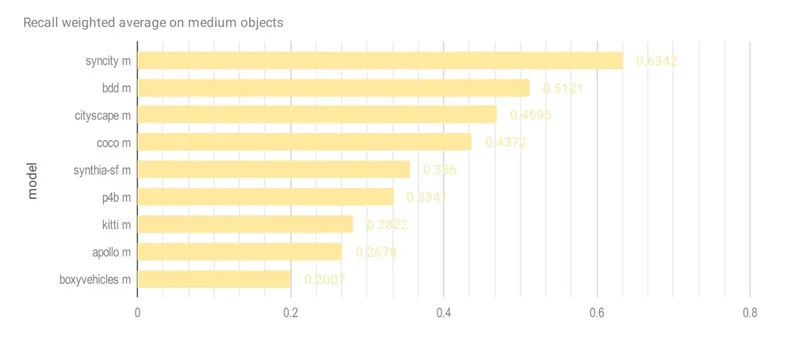
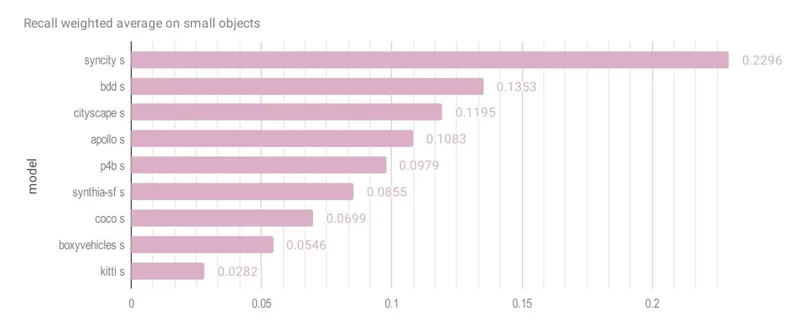
CVEDIA’s SynCity model achieved the highest scores across all object sizes:
| Size | SynCity mAP | Next Best |
|---|---|---|
| Large | 0.8085 | COCO (0.6759) |
| Medium | 0.5792 | BDD (0.4530) |
| Small | 0.2199 | BDD (0.1408) |
Precision by Object Size
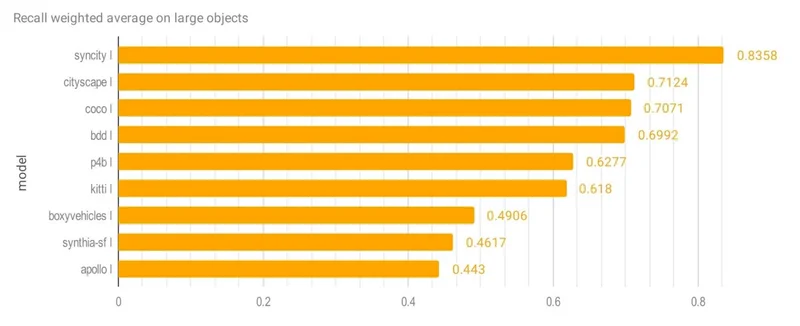
Recall by Object Size
Conclusion
As shown in the confusion matrix tables, CVEDIA’s synthetic algorithm performed substantially better than algorithms created from major open source datasets when challenged by different domains and novelty features. The CVEDIA algorithm was able to retain the majority of the existing features from the backbone model and even indirectly improve them beyond the original dataset metrics.
This shows a new method for algorithm creation as no real data or manual labelling was required to reach our scores, allowing for the ability to virtually solve data requirements with carefully developed synthetic techniques.
Our team also noted that the addition of real data to the CVEDIA training set increased scores beyond what is seen here - which is worth exploring in future tests and a potential strategy for machine learning teams.
Key Takeaways
- Synthetic data outperforms real data cross-domain: CVEDIA’s synthetic algorithms achieved 0.5359 mAP vs. the next best (BDD) at 0.4175 - a 28% improvement
- No real data required: The CVEDIA model was trained exclusively on synthetic data yet outperformed all real-world datasets
- Better generalization: Cross-domain performance is where synthetic data truly shines, as it’s not biased to a single camera, location, or condition
- Scalable solution: Synthetic data eliminates the need for costly data collection and manual annotation while delivering superior results